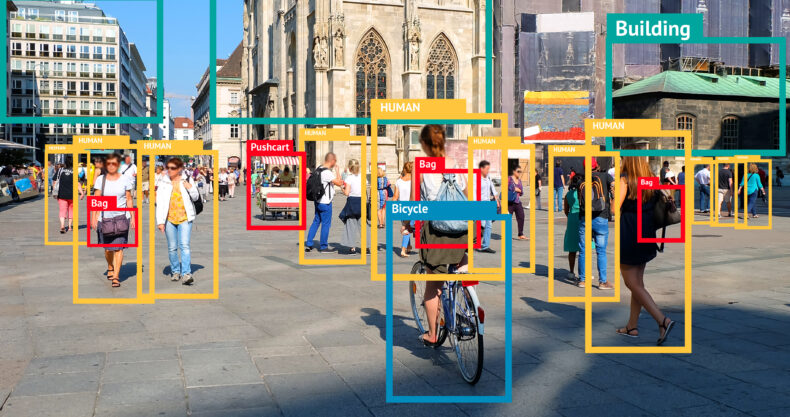
Object Detection(物体検出)とは
Object Detection(物体検出)とは「画像や動画から物体を検出する技術」です。具体的にはバウンディングボックスと呼ばれる枠とラベルで、画像中の物体に対して位置決定とクラス分類を行います。Object Detectionを利用することで私たちは「画像中のどこに何があるか」を機械的に把握することができます。またボックス数を数えることで「対象の物体がいくつあるか」も推定できます。
image classification, image segmentationとの違い
object detectionとimage classificationや image segnmentationの違いは予測対象が異なる点です。以下の画像に示す通り、object detection(
)はバウンディングボックス、image classification(左上) は画像、image segmentation(下2つ) はピクセルのクラスをそれぞれ予測しています。imge clssificationとimage segmentationについては過去の記事で触れているのでそちらをご覧ください
(image classification → https://carbgem.com/plus/wp-digital-imageclassification/)
(image segmentation → https://carbgem.com/plus/wp-imagesegmentation/)

(参考:https://cvml-expertguide.net/terms/dl/instance-segmentation/)
Object DetectionはImage Classificationと比べて、「予測対象が画像のどこに位置しているかが分かり」、「一枚の画像から個体ごとに異なるクラスや予測確信度を出力する」ため、物体の位置や数を知りたいときや、一枚画像に複数の異なるクラスの物体が映っているときに有効です。またImage Segmentationと比べて、「教師ラベル作成の手間が少なく」「予測確信度が分かる」ため、教師ラベルがなく形状などを重視しないときや、病変の検出など予測対象の位置と予測確信度を同時に知りたい時などに使われます。
一般的な活用事例
Object Detectonは例えば以下のような用途で利用されています。
・製品の外観不良検知
製造ラインの過程で製品を撮像し、写真データの中からひびや汚れといった外観不良を検知する。
・自動運転
クルマに搭載されたカメラで周囲の状況を撮影し、その画像に映る標識や障害物などを認識することで車の運転を自動制御する。
・固定カメラを使った計測
店内カメラを使って顧客の数や動向を調査したり、路上カメラを使って走行する車の台数をリアルタイム計測したりする。計測結果はマーケティングや渋滞予測に利用する。
How does Object Detection work?
Object Detectionの歴史
Deep Learningが登場する以前の物体検出では、タスクを「領域探索」「特徴量抽出」「機械学習」の3つに分割して行っていました。まず物体が画像中のどこにありそうかを絞り込んで(領域探索)、次に検出する物体に合わせて特徴量を抽出し、最後に物体が何であるかを分類(機械学習)するといった流れです。この方法では検出対象に合わせて特徴量を設計するため、特定の物体しか検出できない上に最適な特徴量の設計が難しいという問題がありました。その後Deep Learningの登場により、手動で行っていた特徴量抽出を自動で行えるようになりました。このタイプの代表モデルがR-CNNや、R-CNNを改良したFast R-CNNです。これらのモデルは特徴量抽出の課題を克服しましたが、領域探索に時間がかかるため動画解析などには利用できませんでした。そこで登場したのが入力から出力までを一気にDeep Learningで行うEnd-to-Endモデルです。これらのモデルは特徴量抽出だけでなく領域探索までDeep Learningで行うことにより、更なる高速化と汎化を実現しました。

(引用:https://karaage.hatenadiary.jp/entry/2018/03/28/073000)
代表的なモデル
End-to-Endで物体検出できる有名なディープラーニングモデルには「Faster RNN」「Yolo」「SSD」「RetinaNet」等があります。
・Faster R-CNN
Faster R-CNNは、R-CNNを速度改善したFast R-CNNをさらに高速化したモデルであるためFasterという名前になっています。R-CNN、Fast R-CNN、Faster R-CNNそれぞれのモデル構造は以下のようになっています。

R-CNNではSelective Serachという手法で領域探索し、候補領域に対してCNNを用いてクラス分類を行うことで物体を検出します。Fast R-CNNは、R-CNNにRoI poolingとMulti-task Lossというアイデアを採用することで演算時間を大幅に縮めました。VGG16を用いた検証では、R-CNNの「9倍の学習速度・213倍の識別速度」を実現しています。Faster R-CNNは、Fast R-CNNのSelective SerachをRegion Proposal Network (RPN) に置き換えたモデルで、領域探索もCNNで行います。物体検出では初めてEnd-to-Endで学習できるようにしたモデルであり、システムが前後に分断されていない分、Fast R-CNNよりもさらに高速かつ高精度に検出できるようになりました。

• Region Proposal Network (RPN)
RPNでは、まず画像全体の特徴マップからk個の中心が同じでアスペクト比が異なる探索窓(Anchor)を切り出します。k個の候補領域に対し、物体かどうかの分類とバウンディングボックスの設定を行うため、cls layer とreg layerの2つの全結合層へ分岐します。cls layerはオブジェクトか背景かの確率を推定した2k個のスコアを出力し、reg layerは、バウンディングボックスの座標(x,y)・サイズ(w,h)を表す4k個のスコアを出力します。RPNはAnchorごとに判定し、物体である可能性が高いものはFast R-CNNと同様にRoIプーリング以降のネットワークへと進み、物体の分類が行われます。
YOLO
YOLO(You Only Look Once)は、領域探索を分類問題ではなく回帰問題として処理するモデルで、領域探索とクラスの識別を同時に行うことで、リアルタイムに近い処理速度を実現しています。YOLOではまず入力画像を正方形にリサイズし、画像全体をN×N(※N:任意の数)の領域に分割します。続いて、その領域ごとに物体のクラスを推定し、class probability mapを出力します。

(参考:https://www.slideshare.net/ssuser07aa33/introduction-to-yolo-detection-model)
これに並行してバウンディングボックスの推定を行います。分割した領域ごとにB個のバウンディングボックスを推定します。1つのバウンディングボックスにつき、中心座標(x, y)、サイズ(w, h)、物体のコンフィデンス・スコア(背景なら0、物体なら1の確率)の5つの値を出力します。

最後に、推定したClass probability mapとバウンディングボックスの2つを結合し物体を検出します。これらのバウンディングボックスには重複領域が多くあるため、閾値以上の重複があるボックス群に対しては最も信頼度スコアの高いボックスのみを採用します。

SSD
SSD(Single Shot MultiBox Detector)はYOLOのように領域探索とクラスの識別を同時に行いますが、Faster R-CNNのように領域探索に中心が同じでアスペクト比が異なる探索窓を使うことで、小さい物体や低解像度の画像に対する検出率を高めたアーキテクチャです。つまり、YOLOとFaster R-CNNのいいとこどりをしたようなモデルです。

YOLOは元画像を等間隔に区切った領域に対してバウンディングボックスを推定するのに対し、SSDでは異なるスケールの特徴マップに対してデフォルトボックスと呼ばれるアスペクト比の異なる短形窓を置いて、バウンディングボックス候補とします。
そしてデフォルトボックス毎に「バウンディングボックスの位置と形状(loc:localization)」・「カテゴリスコア」を予測します。予測値からバウンディングボックスの誤差関数(localization loss)と物体カテゴリの誤差関数(confidence loss)を計算し、二つの誤差関数の過重合計をモデル全体の損失としています。
評価指標
Object Detectionモデルの評価には主にmAP(mean Average Precision)が使われます。mAPの計算には、IOU、Precision、Recall、Precision Recall Curve、APの値を使います。
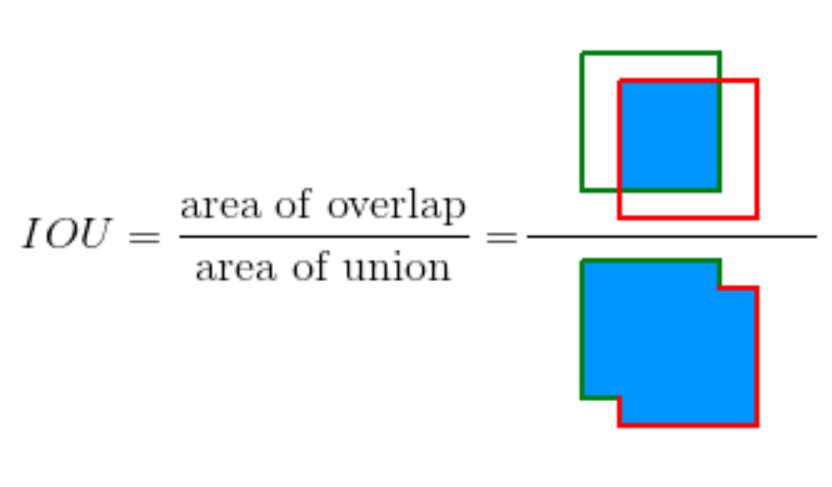
IOU
IOUは領域がどのくらい重なっているかを示す指標で以下の式で計算されます。物体検出では、バウンディングボックスのラベルと予測値から計算されるIOUの値から、物体を正しく検出できているかを判定します。判定には閾値を設定する必要があり、例えばmAP50であればIOU50以上で正解とみなします。閾値が大きくなるほどより正確にバウンディングボックスを検出する必要があり、判定は厳しくなります。
PrecisionとRecall
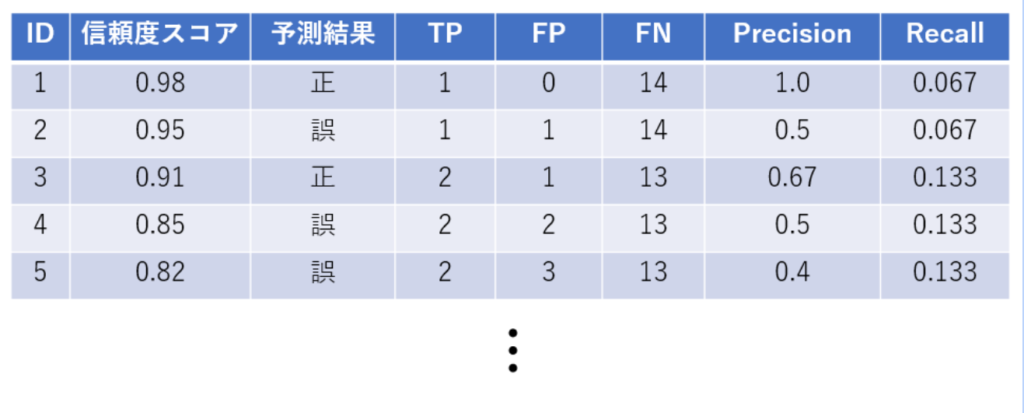
PrecisionとRecallの計算にはIoUの値を使います。IoUが閾値以上のボックス数をTP(True Positive)、閾値に満たないボックスをFP(False Positive)、検出されていない物体の数をFN(False Negative)として、PrecisionとRecallは以下の式で計算します。Precisionは全ての検出のうち正しく検出しているものの割合、Recallは全ての検出対象のうち正しく検出されたものの割合を表しています。
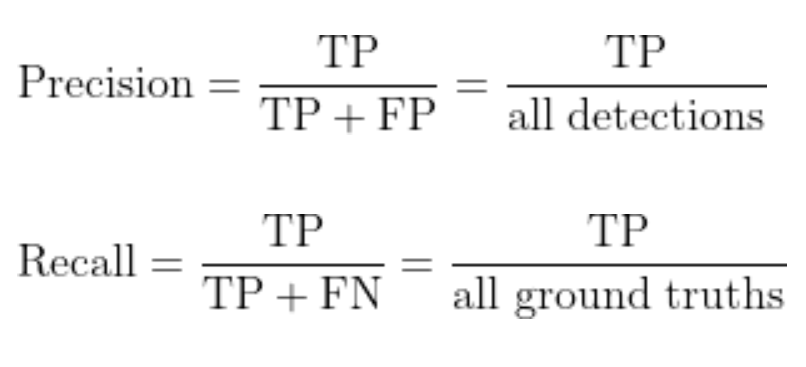
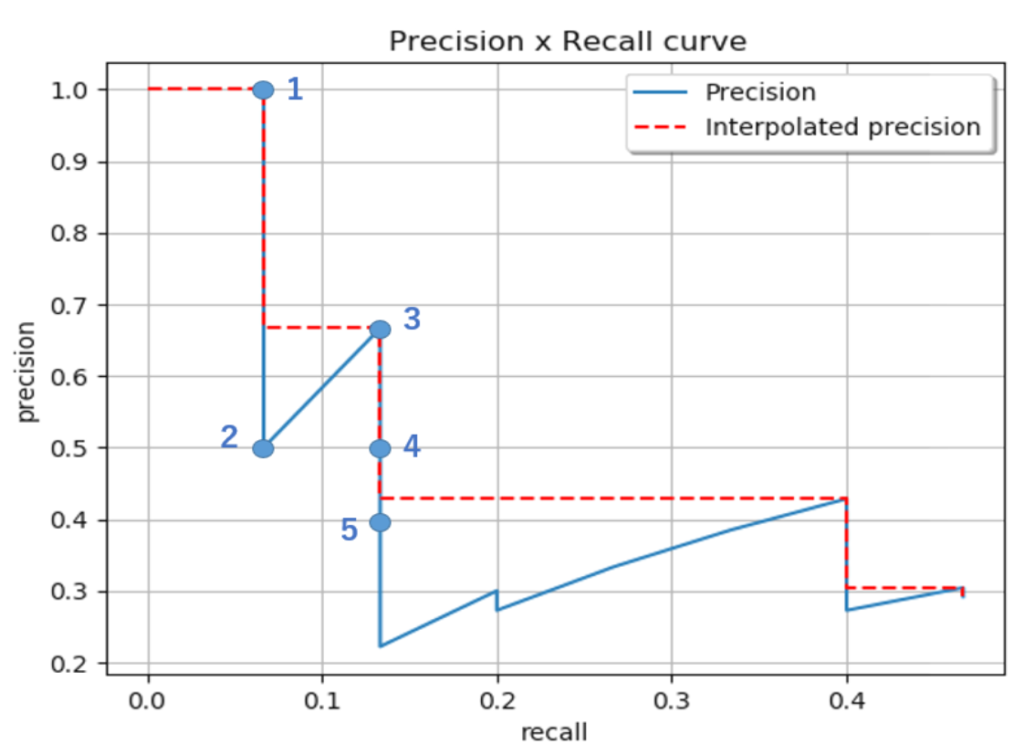
Precision Recall Curve
縦軸にPrecision、横軸にRecallをプロットしてつなげたものがPrecision Recall Curveです。プロットには予測したバウンディングボックスの信頼度スコアを使います。信頼度スコアはそのボックスが物体をどれくらいの確率で含んでいるのかを表すスコアです。まず初めに検出したボックスを信頼度が高い順に並べます。次に信頼度スコアの高い値から順に、その信頼度を超える予測に対するPrecisionとRecallを求めてプロットします。これを全ての信頼度スコアに対して行い、プロットしたものがPrecision Recall Curveです。
PrecisionとRecallは基本的にトレードオフの関係にあり、信頼度スコアの閾値となる値が下がるにつれてFNが減ってRecallは大きくなりますが、FPは増えてPrecisionが小さくなる傾向にあります。しかし、優秀な機械学習モデルの場合、信頼度スコアの閾値が下がってもPrecisionは高いままで維持されます。そのため、カーブが右上に行くほど優秀な機械学習モデルであると言えます。
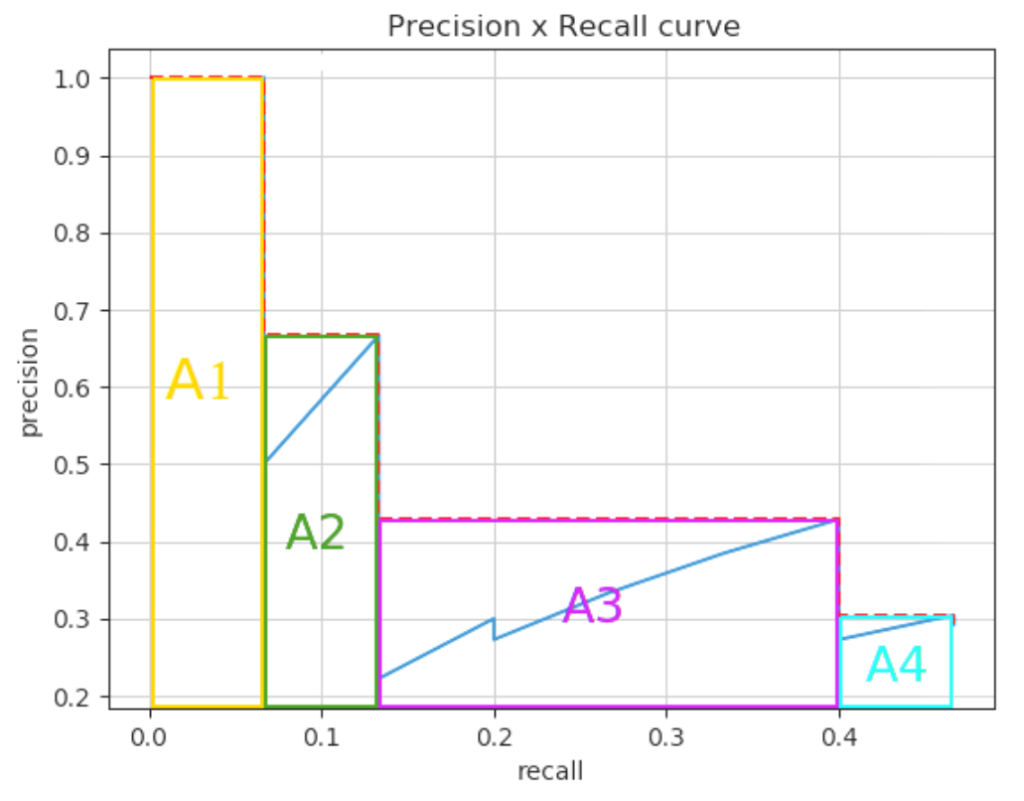
AP
APはPrecision Recall Curveの面積(A1~A4の面積の合計)を示します。カーブが右上に行くほど面積は大きくなるので、数値が大きいほどモデルの性能は良くなります。APを全てのクラスについて平均化したものがmAPであり、これが物体検出の評価指標になります。
(参考:https://www.slideshare.net/ssuser07aa33/introduction-to-yolo-detection-model)
Use case in life science field
医療分野では様々な医用画像から病変や細胞などを検出するためにObject Detectionが利用されます。たとえば、読影医は病変の検出により、動脈瘤や結節、骨転移などの見落としが多い病変に対して見落としのリスクを軽減できます。また病理医は細胞や血球といった数が多く計測が煩雑な物体の検出により、それらを手早く機械的にカウントすることができます。製品化されているサービスには、胸部CT画像から胚結節を検出するもの、内視鏡画像から大腸ポリープを検出するもの、咽頭画像からインフルエンザ濾胞を検出するものなどがあり、今後も様々なサービスの登場が期待されます。
Introduction of our project using Object Detection
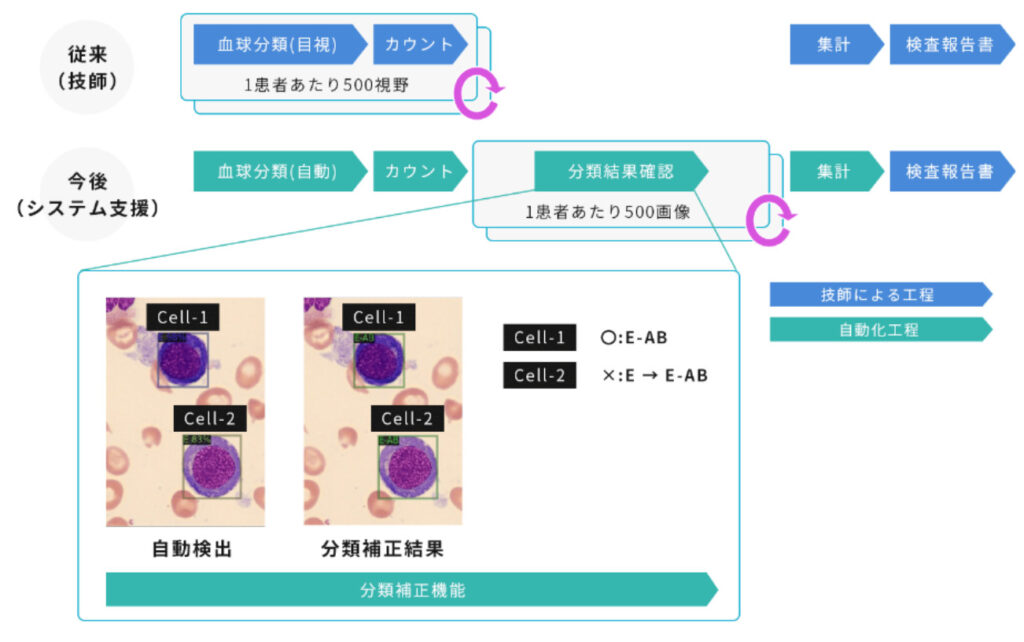
当社グループが提供する「血球細胞の分類支援システム」にもObject Detectionの技術が使われています。
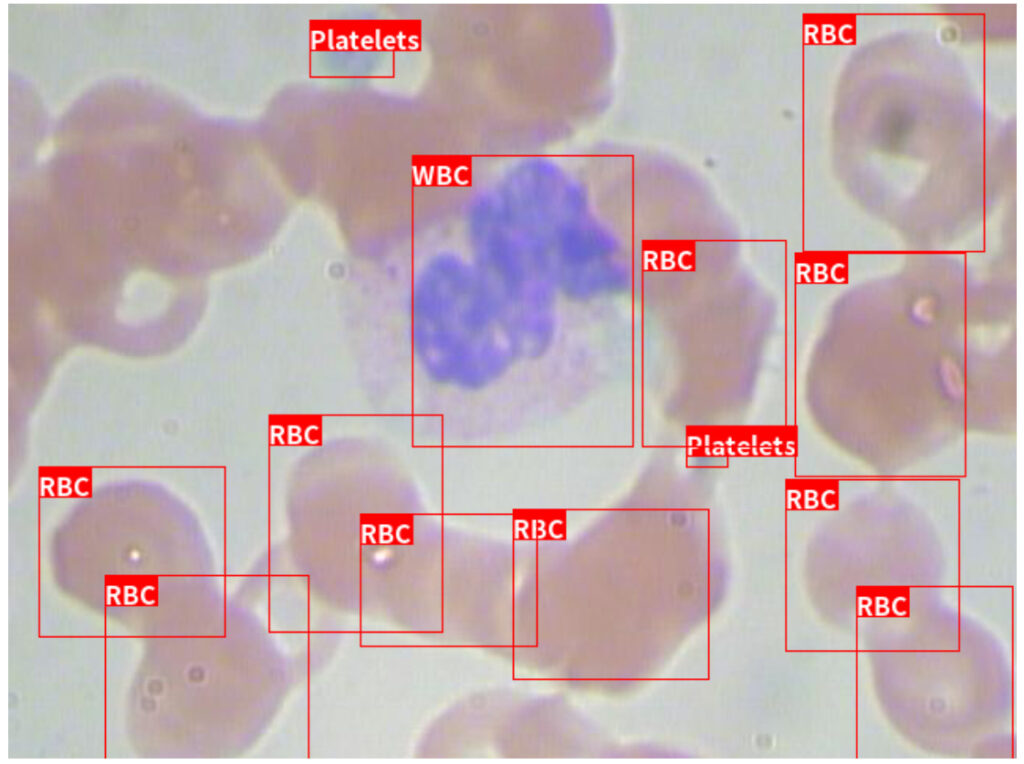
この画像はBCCDデータセットを使用して3種類の血球(血小板、白血球、赤血球)を検出しています。この画像のように「血球細胞の分類支援システム」は、患者あたり約500枚の骨髄スメア画像から30種以上の血球細胞を自動的に検出・分類し、各血球の数を集計します。このシステムで従来は医師が行っていた計測作業を代替することにより、医師の業務負担を軽減し、血球の判定精度を標準化することができます。またクラウドに配置したObject Detectionモデルと連携したSaaSシステムであるため、遠隔の医師との相談や、病院内でも離れている医師と技師間で効率よく情報共有することが可能です。
まとめ
以上、Object Detectionのモデルや事例について、当社グループの取り組みも交えて紹介しました。Object Detectionの手法の進化は著しく、活用法も色々なパターンが提案されています。ぜひ最新情報をキャッチして、研究や業務に活かせそうなものを探してみてください!
【ホワイトペーパー/AIシリーズの記事】
1)Machine Learning for Medical Applications
2)DeepLearning (入門編)
3)Deep learning(上級編)
4)Image Classification(医用画像分類のAI)
5)Image segmentation(領域抽出)
6)What is Object Detection?(物体検出とは?)
7)Explainable AI model(説明可能なAIモデル)
8)医療画像AIにおけるDomain shift