What is Deep Learning?
Deep Learningはプログラムでコーディングするのが難しい直観的な問題をコンピュータが解決するために開発された学習手法です。
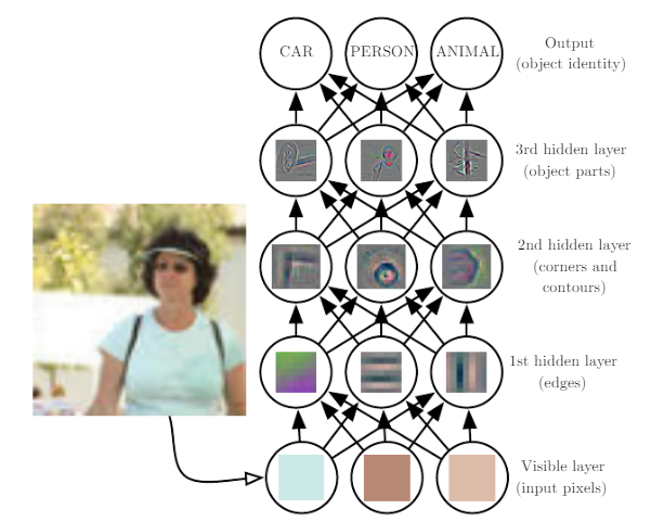
DeepLearningでは、その他の機械学習手法と違って、学習に使用するデータから特徴量をコンピューターが自動的に抽出します。また、対象データの全体像から細部まで様々な粒度の情報を、階層構造として関連させて学習させています。
こうした階層同士の関係を図表で表したときに、その図表が深く多くの層を持つことから、このような手法全般をDeep Learningと呼びます。
Goodfellow-et-al, 2016, ”Deep Learning”,MIT Press,\url{http://www.deeplearningbook.org, p6
AI・MachineLearning・DeepLearningの変遷
Artificial Intelligence(AI)、Machine learning、Deep Learningの言葉の関係は、以下図2のようになっており、コンピュータサイエンスの歴史と関連しています。
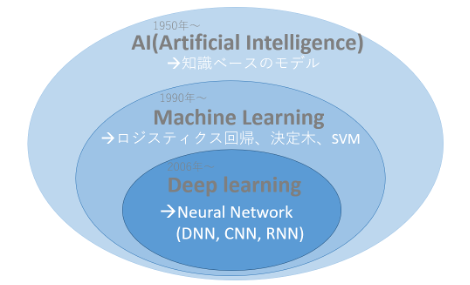
Machine Learningが登場する以前のArtificial Intelligence(AI)はsymbolic AIと呼ばれ、データを処理するための大量のルールをプログラマが手作業で組み込んで作っていました。こうしたAIはチェスや将棋のようにルールが明確な問題に対しては優れた成績を残す一方で、画像分類や音声認識、言語の翻訳のようにコーディングできない複雑で曖昧な問題を解くことは不可能でした。
そこでsymbolic AIに代わる新しいアプローチとして登場したのがMachine Learning(機械学習)です。Machine Learningの登場により、コンピュータはデータから特徴的なパターンを抽出し、自動でルールを学習することができるようになりました。こうしたMachine Learningのアルゴリズムの精度は、学習に使用するデータがどんな情報を持ち、どんな数値で与えられるかに依存しています。学習に使用するデータは特徴量と呼ばれ、従来のMachine Learningではこうした特徴量の設定は人が行っていました。しかし、多くの場合こうした特徴量は直観的で抽象的であるため手動で設定することが難しく、誰が設定するかによって学習精度にばらつきが生じていました。
そこで提案されたのがDeep Learningです。Deep Learningでは、階層的なパターンの同時学習により、直観的で抽象的な特徴量も自動で学習することが可能になりました。Deep Learningの登場により、高精度な予測が行えるだけでなく、特徴量の自動設定により、入力から出力まで人為的な介入が必要なくなりました。
またDeep Learningが注目されている理由は上記に加え、以下の三つが挙げられます。
1.大量のデータと高度な並列計算により成り立つスケーラビリティ
Deep Learningで利用されるDeep Neural Networkは大量の小さな行列乗算によって構成されています。そのため、GPUやTPUでの並列処理に非常に適しており、加えて近年のストレージハードウェアの発展により、大量のデータを用いた学習が可能です。
2.追加データによる学習の更新
Deep Learningモデルは追加データによる学習が可能です。そのため、過去に例をみない新たなデータやデータの傾向が変化した際に、一からモデル学習し直す必要がなくなり、継続的な学習の改善が見込めます。こうした特徴により、Deep Learningは継続的なオンライン学習等で効果を発揮します。
3.学習済みモデルの再利用可能性
Deep Learningは学習済みモデルを別の目的に再利用することが可能です。例えば、犬の画像を分類するために訓練されたDeep Learningモデルを猫の画像を分類するモデルに再利用することができます。このようなモデルを再利用した学習を転移学習といいます。
こうした特性からDeep Learningの技術は、画像処理、音声認識、自然言語処理、時系列解析といったさまざまなタスクに対して、幅広いフィールドで利用されています
How does Deep Learning work?
Deep Learningでは主にDeep Neural Networkと呼ばれるモデルを使って、階層的なデータ変換と特徴量抽出を行なっています。
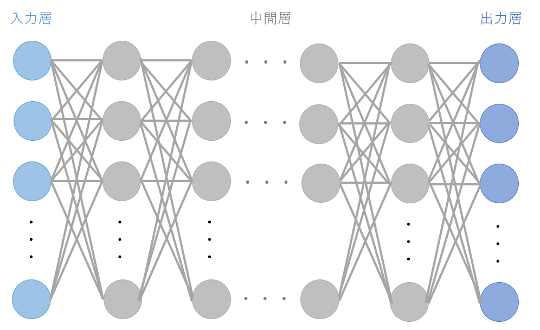
Deep Neural Networkは、Neural Networkと呼ばれる人間の脳神経回路を模して設計されたネットワーク状のモデルが何層にも積み重なったものです。
Neural Networkを構成しているのは、ニューロン(神経細胞)を模して設計されたパーセプトロンと呼ばれる数理モデルです。(図3)ニューロンが複数の電気信号を受け取り一定以上で発火するように、パーセプトロンは複数の入力値(x)に対しそれぞれの重み(w)を乗算し、それらの総和にバイアス項(b)を足した値がしきい値を超えた場合にのみ次のノードに出力(y)を渡します。
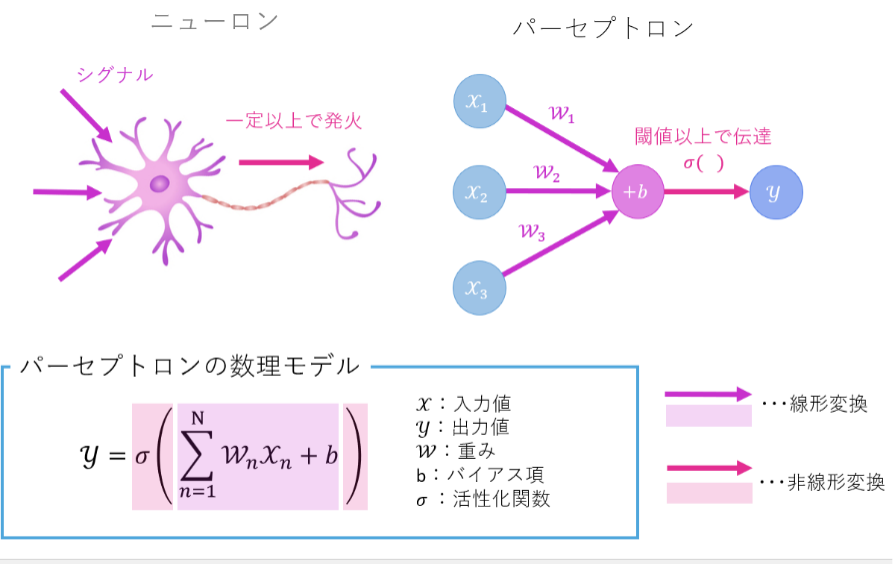
Neural Networkはパーセプトロンから構成されるネットワーク状のモデルです。すべての入力値に対し、パーセプトロンの数理モデルを適用して1つの値を出力します。これを重みを変えながら任意の回数(n回)行い、出そろったn個の値が1つ目の中間層の値となります。これらの値は次の層の入力値となり、同様にパーセプトロンによる線形変換が行われます。こうしたデータ変換を層の数だけくりかえし、最後の出力層では問題に対する予測値を出力します。予測値と目的値(問題に対する答えとなる値)から、損失関数に基づいて損失値が計算されます。損失値は、予測値が目的値とどれくらいかけ離れているかを表すものです。これらの損失値は学習のフィードバックとして用いられ、次回の損失値が今回の損失値より小さくなるようにすべての重みが更新されます。
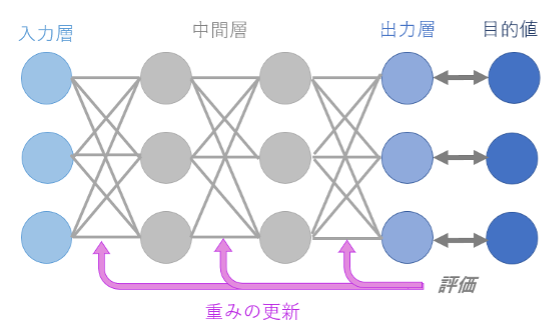
この重みの更新は勾配の計算によって行われます。勾配とは損失関数を重みで微分した値で、現在の重みにおける損失関数曲線の傾きを表します。現在の重みを勾配とは逆方向に動かすことによって、新しく設定された重みではより小さい損失値をとるようになります。このような手順でNeural Networkによるデータ変換と勾配による重みの更新をくりかえすことによって、損失値は徐々に最小値に近づいていきます。こうした重みの更新手法を勾配降下法と言います。
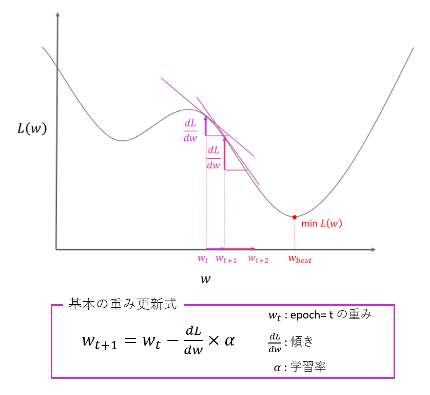
これがNeural Networkによる学習の基本的な原理です。Deep Neural Networkは、このNeural Networkの中間層を多層化(Deepに)したものです。多層化することによってモデルはさまざまな粒度のパターンを学習できるようになります。このNeural Networkの仕組みを利用したモデルに、CNN(Convolutional neural network)やRNN(Recurrent neural network)があり、CNNは主に画像処理の分野、RNNkは主に自然言語処理の分野で広く利用されています。
参考文献: François Chollet・著. 巣籠悠輔監・訳. PythonとKerasによるディープラーニング. マイナビ出版. 2018. (https://book.mynavi.jp/ec/products/detail/id=90124)
Current Trends of Deep Learning
近年のDeep Learningに関連する技術としては「Transformer」と呼ばれるモデルが一躍脚光を浴びています。「Transformer」は2017年12月に発表された自然言語処理に関する論文 ”Attention Is All You Need” で初めて紹介されました。このモデルはDeepLeraningではありますが、NeuralNetoworkを一切使用せず、「Attention」と呼ばれるデータ間の関連度を計算する数理モデルを利用しています。Transformerを用いた学習は学習速度が速いだけでなく予測精度も高いため、その後登場する多くのモデル(BERT、XLNet、T5)に応用されています。発表当初は機械翻訳タスク等の自然言語処理にのみ使われていましたが、近年では「Vision Transformer」といって画像処理分野でもその利用が広まっています。気になる人は是非原著論文を読んでみてください。
(Vaswani, A. et al. 2017. “Attention Is All You Need”) 論文ページ:https://arxiv.org/abs/1706.03762
Introduction of our project using Deep Learning
弊社が提供するソリューションを例にDeep Learningの技術がどのように使われているか?実際の事例を2つご紹介したいと思います。
「胚のタイムラプス画像解析による妊娠・出産可能性予測システム」
このシステムは、胚培養過程のタイムラプス画像の入力に対し、妊娠・出産可能性を5段階で評価した結果を出力します。このシステムではResNetと呼ばれるDeep Learningモデルを用いて、画像の特徴を学習し妊娠・出産の関連を予測しています。システムに導入されているモデルは、約二万症例の胚培養過程のタイムラプス画像と妊娠・出産アウトカムの関連性から、胚の生育過程および胚の形態学的特徴量を学習しています。そのため移植対象となる胚に対してタイムラプス画像を活用し、胚の生育過程および形態学的特徴量を認識し、妊娠・出産アウトカムを予測します。さらにこのシステムでは、タイムラプス画像を用いたモデルによる予測結果と画像以外の臨床データをランダムフォレストと呼ばれる機械学習モデルを用いてアンサンブル学習させることによって、予測精度を高めることに成功しています。
https://onlinelibrary.wiley.com/doi/10.1002/rmb2.12443
「造血幹細胞移植時のドナー/レシピエントマッチングシステム」
このシステムは、悪性血液疾患などに対する造血幹細胞移植に際し、臍帯血バンクや骨髄バンク等の移植ドナーの情報とレシピエントである患者の前処置情報から、個々のドナー候補に応じて患者の予後を予測するものです。
このシステムに用いられるモデルは、スタックアンサンブルモデルと呼ばれ、1種の統計学的手法(Cox比例ハザードモデル)と7種の機械学習法(Random Survival Forest, Dynamic DeepHit, ADABoost,XGBoost, Extra Tree Classifier, Bagging Classifier, and GradientBoosting Classifier)で得られた予測モデルをスタッキングと呼ばれるアンサンブル学習手法を用いて融合させることにより構築されます。このアンサンブルモデルを構築する7種類の機械学習モデルのうちの一つが、 Dynamic DeepHitと呼ばれる、時系列データから生存確率を予測するために開発されたDeep Learningモデルです。このアンサンブルモデルは、従来のCOX比例ハザードモデルと比較して、全生存、再発、GVHD、GRFS(Gvhd-free,Relapse-Free Survival)のすべての指標において優れた予測精度(C-index)を獲得しています。
Discussion
今回はDeep Learningの概要について書きました。次回はDeep Learning上級編として、モデル学習時の流れやモデル学習時に設定するハイパーパラメータ(損失関数など)を紹介したいと思います。また、学習をさせる上で重要な問題となる、モデルの「過学習」とその対策についても解説します。過学習とは、モデルが学習データの特徴を学習しすぎた結果、未知のデータに対する予測性能が下がってしまうことです。どのような流れでモデルに学習させるのか?どのように過学習を防ぐのか?気になる方はぜひ次回の記事もご覧ください。
【ホワイトペーパー/AIシリーズの記事】
1)Machine Learning for Medical Applications
2)DeepLearning (入門編)
3)Deep learning(上級編)
4)Image Classification(医用画像分類のAI)
5)Image segmentation(領域抽出)
6)What is Object Detection?(物体検出とは?)
7)Explainable AI model(説明可能なAIモデル)
8)医療画像AIにおけるDomain shift