Deep Metric Learning(深層距離学習)とは
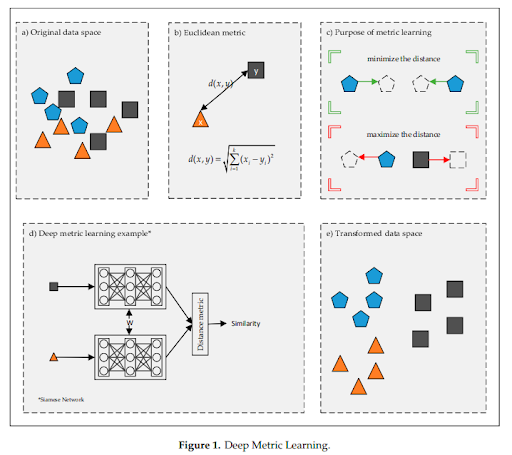
Deep Metric Learningは、深層学習を使用してデータ間の距離や類似性を学習する手法です。距離学習は生データ(a)からデータ間の距離や類似度を計算し(b)、同じクラスのデータは近づき、異なるクラスのデータは遠ざかるように重みを更新することで(c)、データを効果的に表現する埋め込み空間(embedding space)を学習します(d)。これにより、埋め込み空間では同じクラスに属するデータは近くに配置され、異なるクラスに属するデータは遠くに配置されます(e)。この空間における、データ間の距離はそれらの類似性を反映します。近年は深層学習の発展に伴い、深層学習と距離学習を組み合わせた様々なDeep Metric Learning手法が提案されています。
一般的なクラス分類との違い
- 目的
一般的な分類タスクでは、データポイントを正しいカテゴリに割り当てることが目的です。一方、Deep metric learningでは、データポイントの類似性を表現する埋め込み空間を構築し、類似するデータポイントを近くに配置し、異なるデータポイントを遠くに配置することが目的です。
- 入力データ
一般的な分類タスクでは、データセットには各データポイントに対して正しいラベルが付与されています。例えば、猫と犬の画像を分類するタスクでは、各画像には「猫」と「犬」というラベルが与えられています。
一方、Deep metric learningでは、学習には通常、ラベルのペアやトリプレットが必要です。ラベルのペアは、2つのデータポイントとそれらの類似性を示すラベル(例: 1 or -1)から構成されます。例えば、同じ人物の顔写真のペアには「1」というラベルが付けられ、異なる人物の顔写真のペアには「-1」というラベルが付けられます。トリプレットは、3つのデータポイントから構成され、アンカーデータポイント、正例データポイント、負例データポイントと呼ばれます。アンカーデータポイントと正例データポイントは同じクラスに属し、アンカーデータポイントと負例データポイントは異なるクラスに属します。トリプレット学習では、アンカーと正例の間の距離を縮め、アンカーと負例の間の距離を広げるような学習を行います。
このようにDeep metric learningでは、ラベルのペアやトリプレットを使用することで、類似性や距離を学習するための情報を提供します。これにより、埋め込み空間上でのデータポイントの関係性を学習することができます。
- 学習手法
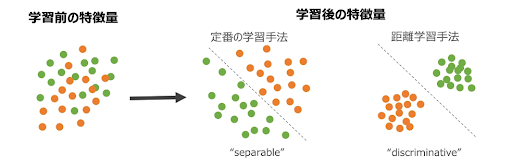
一般的なクラス分類では、特徴量抽出の際にはサンプル間の距離は考慮せず、全結合層で分離可能(separable)な特徴量を学習します。この学習手法では、訓練データに各クラスのサンプル数が十分に含まれている場合に高い精度を達成できますが、訓練サンプルの少ないクラスや未知のクラスには適していません。
一方、Deep metric learningでは、同じクラスのサンプル間の距離を大きくし、異なるクラスのサンプル間の距離を小さくするように学習します。これにより、識別的(discriminative)な特徴量が得られます。距離学習の手法を用いることで埋め込み空間上で各クラス間の特徴ベクトルに距離が生じるため、訓練サンプルの少ないクラスや未知のクラスを識別することもできるようになります。
学習手法
一般的な深層距離学習は以下の手順で学習します。
- 複数クラスにクラス分けされた学習データを用意する。
- 全データの中から2 or 3つのデータポイントを取り出す。
- 2 or 3つのつのデータポイントを別々に同一のモデルに通して、埋め込み空間における変換後のデータポイント(特徴ベクトル)を得る。
- 2つのデータポイントが同じクラスに属していれば(positive)特徴ベクトルが「近く」なるように、異なるクラスに属していれば(negative)特徴ベクトルが「遠く」なるようにモデルのパラメータを変える。
- 学習が収束するまで2~4を繰り返す。
4において、特徴ベクトルの「近さ・遠さ」を測る方法は大きく二つに分けられます。一つはユークリッド距離を使った手法で、もう一つは特徴ベクトル間の角度を使用した手法です。
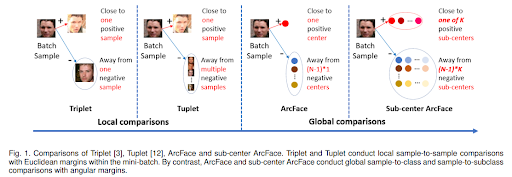
2016年あたりまでは損失関数にユークリッド距離を用いた手法が一般的でしたが、この方式は有効な学習データの選択が難しいという欠点もありました。一方、2017年あたりからはソフトマックス損失関数(Softmax Cross Entropy Loss)の改良型を用いた角度系が流行りました。角度系はユークリッド距離系のように適切なサンプルを選択する必要がなく、通常のクラス分類と同様に距離学習が出来るという利点があります。
最近までは角度系の方がユークリッド距離系よりも性能が優れているという見方が多かったものの、二つの手法を厳密に比較をした結果、大した差はないということが分かりました。[2] そのため、二つの手法は状況に応じて使い分けることが求められます。本記事では、ユークリッド距離系で最も一般的なTriplet Loss[3]、角度系で最も一般的なArcFace[4]、最近注目を浴びているAdaCos[5]を紹介します。
- Triplet Loss
埋め込み空間におけるサンプル間のユークリッド距離で損失関数を計算する手法です。この手法は、サンプル選択がモデル訓練の成功と収束性に大きな影響を与えます。また、全ての可能なサンプル組み合わせで訓練すると計算量が非常に多くなるため、効果的かつ効率的に学習できるサンプル組み合わせを選択することが重要です。簡単なサンプル組み合わせ(Easy negative mining)は、訓練の効果が低く時間と計算リソースの無駄使いに繋がるため、やや難しいサンプル組み合わせ(semi-hardまたはhard negative mining)が好まれます。
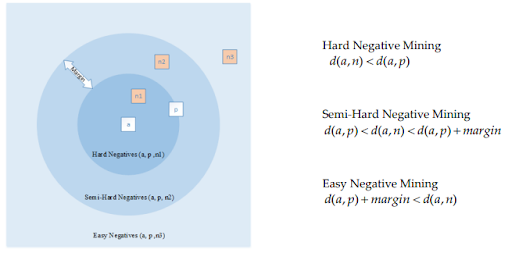
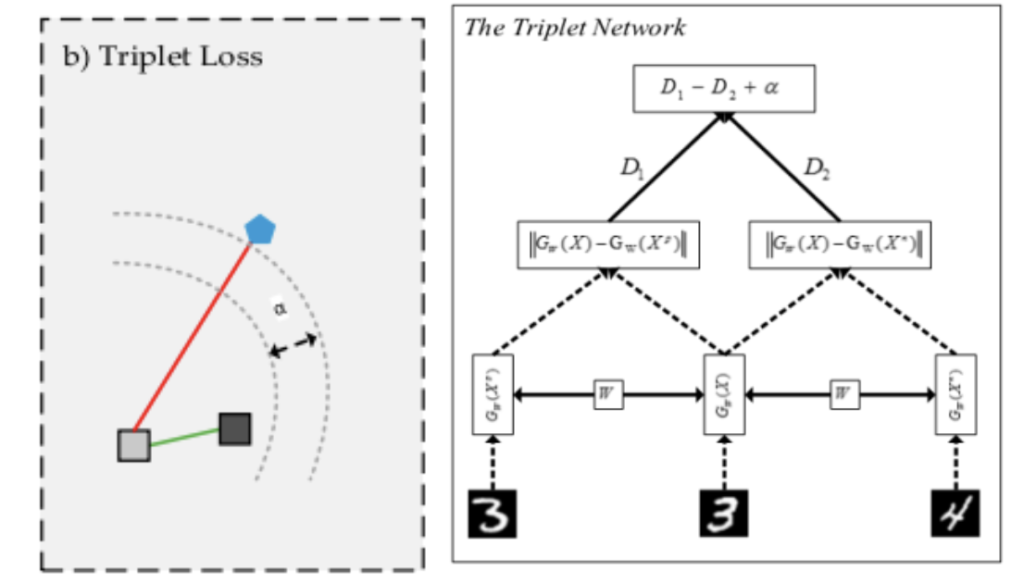
この手法ではトリプレットと呼ばれるデータを入力に使います。各トリプレットは、アンカー、正例、負例の3つの入力で構成されます。アンカーは参照点であり、目標は埋め込み空間内で正例をアンカーに近づけ負例を遠ざけることです。Triplet lossとは、埋め込み空間におけるpositiveペア(アンカーと正例)間の距離(D1)とnegativeペア(アンカーと不例)の間の距離(D2)の差がからマージンαを引いたもので、これが小さくなるようにモデルを学習させます。(図4)
学習にはトリプレットネットワークを使います。トリプレットネットワークは重みを共有する3つの同じニューラルネットワークから構成されます。これら3つのニューラルネットワークにそれぞれ、アンカー、正例、不例、を入力し、特徴ベクトルを出力します。そして出力された特徴ベクトルからTriplet lossを計算し、その値が小さくなるように3つのネットワークの重みを同時に更新します。これによりネットワークは正の距離を最小化し、負の距離を最大化するように訓練され、データの根本的な類似構造を捉える特徴表現を学習できます。Triplet Lossの問題点は学習の成功と収束性がサンプル選択に大きく依存することと、ローカル情報で学習するためです。
- ArcFace
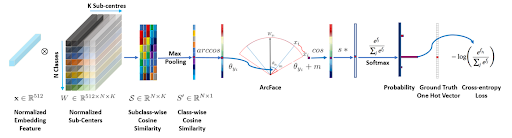
ArcFaceでは従来の分類タスクに使用されるソフトマックス損失関数を応用しています。ソフトマックス損失関数は、分類タスクにおいて正しいクラスに対しては高い確率を、正しくないクラスに対しては低い確率を出力するように働きます。しかし、ソフトマックス損失関数は埋め込み空間における特徴ベクトルの類似度を考慮しないため、そのままでは境界付近のサンプルに対する識別性能が低くなる傾向にあります。そこで、加算角度マージン損失を導入し、埋め込み空間における異なるクラス間の角度分離をより大きくするように設計したのがArcFaceです。これにより、特徴空間内の異なるクラス間の特徴ベクトルに、より広いギャップや角度が生まれます。ArcFaceでは、正規化された特徴ベクトルとクラスの代表ベクトルのコサイン類似度を測定します。この値は-1から1の範囲を取り、1であればベクトルが同一であることを示し、0であれば直交している(相関がない)ことを示し、-1であれば正反対であることを示します。コサイン類似度から計算される二つのベクトルがなす角θyに角度マージンmを加算し、再びコサインに戻します。この値にスケーリングパラメータsをかけた値を用いてソフトマックス損失を計算することで、モデルはクラス間の境界をより明確に学習し、特徴をより正確に識別します。
またArcFaceは、Triplet Lossのような直接的にサンプル間の距離を比較する学習手法と違って、グローバルな情報(クラス中心位置)を利用した学習が可能です。加えて、面倒なサンプル選択の工夫も不要になります。
- AdaCos
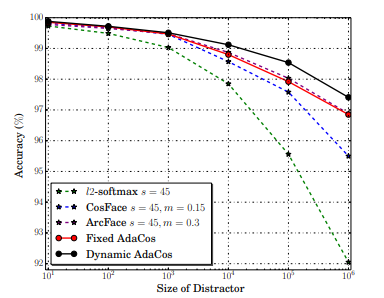
従来の角度ベースのソフトマックス損失においてハイパーパラメータを手動で調整する必要があるという課題がありました。これに対処するために提案された新しい手法がAdaCosです。AdaCosはハイパーパラメータを必要としない角度ベースの損失関数であり、コサイン類似度を動的にスケールすることでスケールパラメータやマージンを自動で最適化します。AdaCosは、追加の計算オーバーヘッドを導入することなく、より高速で安定した学習の収束をもたらします。本論文の著者らは、LFW、MegaFace 1-million Challenge、IJB-Cデータを含む、いくつかの公開顔認識ベンチマークにおいてAdaCosの有効性を実証し、3つのデータセットすべてにおいて、他のソフトマックス損失よりも優れていることを示しました。
Deep Metric Learning の利用例
Deep Metric Learningはコンピュータビジョンや自然言語処理など、さまざまな分野で応用範囲が広く、以下のようなアプリケーションに利用されています。
1. 画像検索: 画像検索システムにおいて、大規模なデータベースから類似画像を効率的に検索するために利用できます。画像間の類似度を学習することで、メトリック学習アルゴリズムは画像検索システムの性能を向上させることができる。
2. 物体認識: 画像中の物体を、既知の物体クラスとの類似性に基づいて正確に分類することができます。
3. 顔認識: 顔の普遍的な特徴表現を学習することで、ポーズ、照明、表情にばらつきがあっても、顔を正確に照合・識別することができます。
4. テキスト分類: 学習に使用したテキストカテゴリとの類似性に基づいて、新しいテキストを正確なカテゴリに分類することができます。
5. 推薦システム: ユーザーやアイテム間の類似性を学習し、好みや特性が類似したユーザーやアイテムを特定することで、パーソナライズされたレコメンデーションが可能になります。
6. クラスタリング: 類似したデータ点をグループ化することができます。これはデータ中の意味のあるパターンや構造を発見するのに役立ちます。
他にも様々な領域での適用が期待でき、たとえば、医療、金融、ロボット工学、ソーシャルメディアなどの領域では、病気の診断、信用リスク評価、物体認識、ユーザーの推薦といったタスク性能の向上に寄与する可能性があります。医用画像においても深層距離学習を用いて推論を行う事例が出てきており、最近では、距離学習を用いてCT画像からCOVID-19の識別を行った論文[6]や、MRI画像から肝硬変の進行状態の分類を行った論文[7]が発表されている。
まとめ
本記事では、最近注目を浴びているDeep metric learningについて解説しました。
- Deep metric learningはデータ間の距離や類似性を学習する
- データの類似性を表現する埋め込み空間を得ることが目的である
- 距離ベースと角度ベースの手法がある
- 角度ベースの手法はサンプル選択が不要である
- 様々なタスクに応用が可能である
Deep metric learningはあらゆる分野・タスクで応用が期待されており、日々さまざまな手法が発表・議論されています。興味を持った人はぜひ色々調べてみてください。
参考文献
[1]Kaya, M., & Bilge, H. Ş. (2019). Deep metric learning: A survey. Symmetry, 11(9), 1066.
[2]]A Metric Learning Reality Check
[6]加藤 聡太, 堀田 一弘, 距離学習を用いたCT画像からのCOVID-19の識別, Medical Imaging Technology, 2021, 39 巻, 1 号, p. 20-26
[7]中井 克啓, 韓 先花, 距離学習を導入した深層学習ネットワークによる肝硬変状態分類の検討, 人工知能学会全国大会論文集, 2021, JSAI2021 巻, 第35回 (2021)